Contents
Introduction
In the previous edition - Binary Search Tree 2 - a large scale experiment on search engine behaviour was staged with more than two billion different web pages. This experiment lasted exactly one year, until April 13th. In this period the three major search engines requested more than one million pages of the tree, from more than hundred thousand different URLs. The home page of drunkmenworkhere.org grew from 1.6 kB to over 4 MB due to the visit log and the comment spam displayed there.
This edition presents the results of the experiment.
Setup
2,147,483,647 web pages ('nodes') were numbered and arranged in a binary search tree. In such a tree, the branch to the left of each node contains only values less than the node's value, while the right branch contains only values higher than the node's value. So the leftmost node in this tree has value 1 and the rightmost node has value 2,147,483,647.
The depth of the tree is the number of nodes you have to traverse from the root to the most remote leaf. Since you can arrange 2n+1 - 1 numbers in a tree of depth n, the resulting tree has a depth of 30 (231 = 2,147,483,648). The value at the root of the tree is 1073741824 (230).
For each page the traffic of the three major search bots (Yahoo! Slurp, Googlebot and msnbot) was monitored over a period of one year (between 2005-4-13 and 2006-4-13).
To make the content of each page more interesting for the search engines, the value of each node is written out in American English (short scale) and each page request from a search bot is displayed in reversed chronological order. To enrich the zero-content even more, a comment box was added to each page (it was removed on 2006-4-13). These measures were improvements over the initial Binary Search Tree which uses inconvenient long URLs.
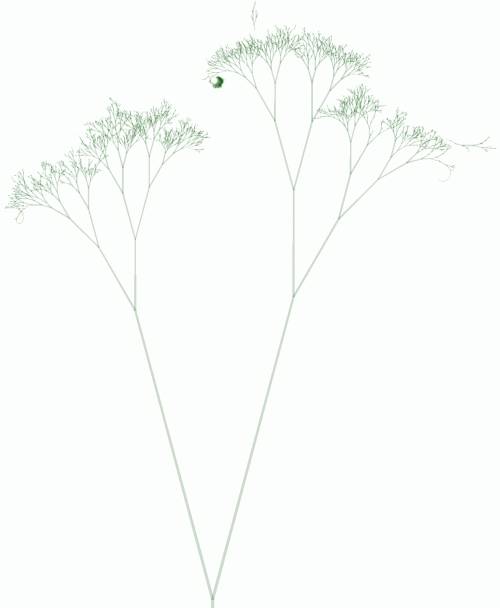
Every node shows an image of three trees. Each tree in the image visualises which nodes are crawled by each search engine. Each line in the image represents a node, the number of times a search bot visited the node determines the length of the line. The tree images below are modified large versions of the original image, without the very long root node and with disconnected (wild) branches.
{kind=link}
Overall results
From the start Yahoo! Slurp was by far the most active search bot. In one year it requested more than one million pages and crawled more than hundred thousand different nodes. Although this is a large number, it still is only 0.0049% of all nodes. The overall statistics of all bots is shown in the table below.
| Yahoo! | MSN | ||
|---|---|---|---|
| total number of pageviews | 1,030,396 | 20,633 | 4,699 |
| number of nodes crawled | 105,971 | 7,556 | 1,390 |
| percentage of tree crawled | 0.0049% | 0.00035% | 0.000065% |
| number of indexed nodes | 120,000 | 554 | 1 |
| indexed/crawled ratio | 113.23% | 7.33% | 0.07% |
The growth of the number of pageviews and the number of crawled nodes over the year the experiment lasted, is shown in figure 1 and 2. The way the bots crawled the tree is visualised in detail with the animations for each bot in the sections below.
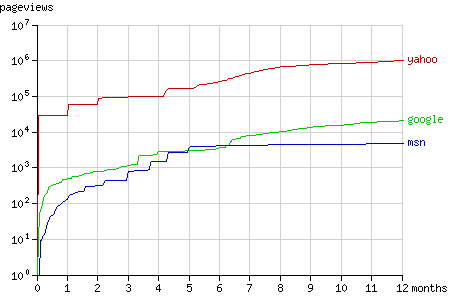
Fig. 1 - The cumulative number of pageviews by the search bots in time.
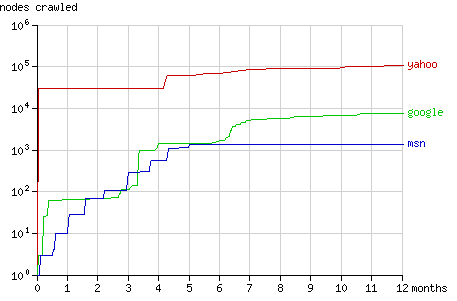
Fig. 2 - The cumulative number of nodes crawled by the search bots in time.
The graph below (fig. 3) shows how many nodes of each level of the tree were crawled by the bots (on a logarithmic scale). The root of the tree is at level 0, while the most remote nodes (e.g. node 1) are at level 30. Since there are 2n nodes at level n (there is only 1 root and there are 230 nodes at level 30) crawling the entire tree would result in a straight line.
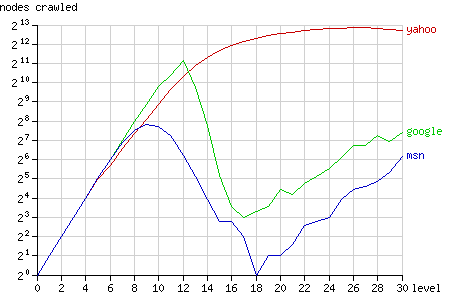
Fig. 3 - The number of nodes crawled after 1 year, grouped by node level.
Google closely follows this straight line, until it breaks down after level 12. Most nodes at level 12 or less were crawled (5524 out of 8191), but only very few nodes at higher levels were crawled by Googlebot. MSN shows similar behaviour, but breaks down much earlier, at level 9 (656 out of 1023 nodes were crawled). Yahoo, however, does not break down. At high levels it gradually fails to request all nodes.
The nodes at high levels that were crawled by Yahoo, were requested quite often compared to the other bots: at level 14 to 30 each page was requested 10 times at average (see fig. 4).
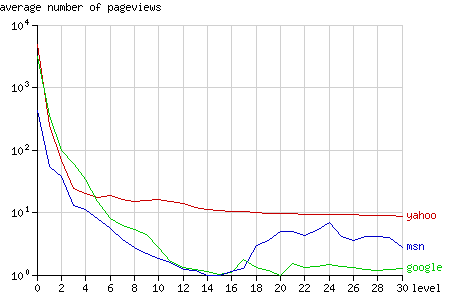
Fig. 4 - The average number of pageviews per node after 1 year, grouped by node level.
Yahoo! Slurp

- large version (4273x3090, 1.5MB)
- animated version over 1 year (2005-04-13 - 2006-04-13, 13MB)
- animated version of the first 2 hours (2006-04-14 00:40:00-02:40:00, 2.2MB)
{kind=link}
Fig. 5 - The Yahoo! Slurp tree.
Yahoo! Slurp was the first search engine to discover Binary Search Tree 2. In the first hours after discovery it crawled the tree vigorously, at a speed of over 2.3 nodes per second (see the short animation). The first day it crawled approximately 30,000 nodes.
In the following month Slurp's activity was low, but after exactly one month it requested all pages it visited before, for the second time. In the animation you can see the size of the tree double on 2005-05-14. This phenomenon is repeated a month later: on 2005-06-13 the tree grows to three times it original size. The number of pageviews is then almost 90,000 while the number of crawled nodes still is 30,000. Figure 6 shows this stepwise increment in the number of pageviews during the first months.
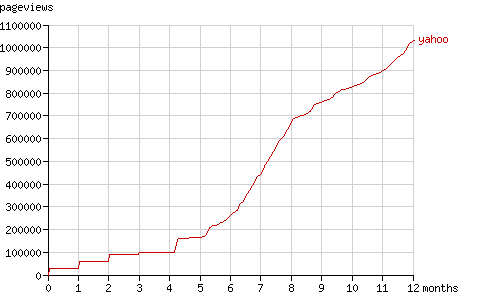
Fig. 6 - The cumulative number of pageviews by Yahoo! Slurp in time.
After four months Slurp requested a large number of 'new' nodes, for the first time since the initial round. It simply requested all URLs it had. Since it had already indexed 30,000 pages, that each link to two pages at a deeper level, it requested 60,000 pages at the end of August (the number of pageviews jumps from 100,000 to 160,000 pages in fig. 6) and it doubled the number of nodes it had crawled (see the fig. 7).
After 5 months Yahoo! Slurp started requesting nodes more regularly. It still had periods of 'discovery' (e.g. after 10 months).
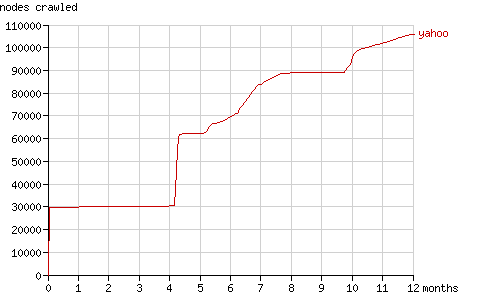
Fig. 7 - The cumulative number of nodes crawled by Yahoo! Slurp in time.
Yahoo reported 120,000 pages in it's index (current value). This may seem impossible since it only visited 105,971 nodes, but every node is available on two different domain names: www.drunkmenworkhere.org and drunkmenworkhere.org.
Note: the query submitted to Google and MSN yielded 35,600 pages on Yahoo. Yahoo is the only search engine that returns results with the query used above.
Googlebot
- large version (4067x4815, 180kB)
- animated version (2005-04-13 - 2006-04-13, 1.2MB)
{kind=link}
Fig. 8 - The Googlebot tree.
In comparison with Yahoo's tree, Google's tree looks more like a natural tree. This is because Google visited nodes at deeper levels less frequently than their parent nodes. Yahoo only visited the nodes at the first three levels more frequently, while Google did so for the first 12 levels (see fig. 4).
The form of the tree follows from Google's PageRank algorithm. PageRank is defined as follows:
"We assume page A has pages T1...Tn which point to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1. We usually set d to 0.85. There are more details about d in the next section. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows:
PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn)) "
Since most nodes in the tree are not linked to by other sites, the PageRank of a node can be calculated with this formula (ignoring links in the comments):
PR(node) = 0.15 + 0.85 (PR(parent) + PR(left child) + PR(right child))/3
The only unknown when applying this formula iteratively, is the PageRank of the root node of the tree. Since this node was the homepage of drunkmenworkhere.org for a year, a high rank may be assumed. The calculated PageRank tree (fig. 9) shows similar proportions as Googlebot's real tree, so the frequency of visiting a page seems to be related to the PageRank of a page.

Fig. 9 - A binary tree of depth 17 visualising calculated PageRank as length of each line, when the PageRank of the root node is set to 100.
The animation of the Googlebot tree shows some interesting erratic behaviour, that cannot be explained with PageRank.
- The rightmost branch
- From the start Googlebot crawled more nodes on the right hand side of the tree.
On 2005-07-04 it tries to visit the rightmost node, i.e. the node with the highest value.
After selecting the right branch starting at the root for 20 levels Googlebot stopped.
This produced the arc at the right end of the tree.

- Searching node 1
- On 2005-06-30 Googlebot visited node 1, the leftmost node.
It did not crawl the path from the root to this node, so how did it find the page?
Did it guess the URL or did it follow some external link?
A few hours later, Googlebot crawled node 2, which is linked as a parent node by node 1. These two nodes are displayed as a tiny dot in the animation on 2005-06-30, floating above the left branch. Then, a week later, on 2005-07-06 (two days after the attempt to find rightmost node), between 06:39:39 and 06:39:59 Googlebot finds the path to these disconnected nodes by visiting the 24 missing nodes in 20 seconds. It started at the root and found it's way up to node 2, without selecting a right branch. In the large version of the Googlebot tree, this path is clearly visible. The nodes halfway the path were not requested for a second time and are represented by thin short line segments, hence the steep curve.

- Yahoo-like subtree
-
On 2005-07-23 Google suddenly spends some hours crawling 600 new nodes near node 1073872896.
Most of these nodes were not visited ever again.
This subtree is the reason the number of nodes crawled by Googlebot, grouped by level, increases again from level 18 to level 30 in fig. 3.

Over the last six months Googlebot requested pages at a fixed rate (about 260 pages per month, fig. 10). Like Yahoo! Slurp it seems to alternate between periods of discovery (see fig. 11) and periods of refreshing it's cache.
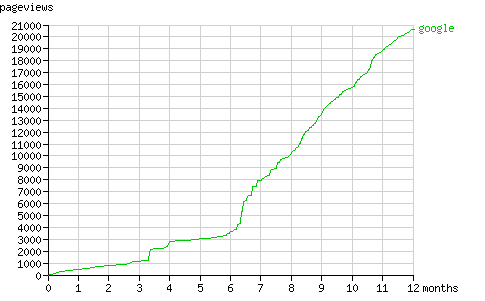
Fig. 10 - The cumulative number of pageviews by Googlebot in time.
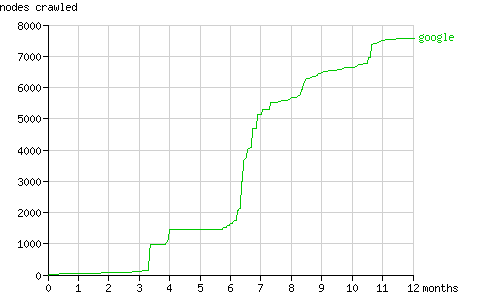
Fig. 11 - The cumulative number of nodes crawled by Googlebot in time.
Google returned 554 results when searching for nodes. The first nodes reported by Google are node 1 and 2, which are very deep inside the tree at level 29 and 30. Their higher rank is also reflected in the curve shown above (Searching node 1), which indicates a high number of pageviews. They probably appear first because of their short URLs. The other nodes at the first result page are all at level 4, probably because the first three levels are penalised because of comment spam. The current number of results can be checked here.
MSNbot

- large version (4200x2795, 123kB)
- animated version (2005-04-13 - 2006-04-13, 846kB)
{kind=link}
Fig. 12 - The msnbot tree
The Msnbot tree is much smaller than Yahoo's and Google's. The most interesting feature is the disconnected large branch to the right of the tree. It appears on 2005-04-29, when msnbot visits node 2045877824. This node contains one comment, posted two weeks before:
I hereby claim this name in the name of...well, mine. Paul Pigg.
A week before msnbot requested this node, Googlebot already visited this node. This random node at level 24 was crawled because of a link from Paul Pigg's website masterpigg.com (now dead, Google cache). All three search engines visited the node via this link, and all three failed to connect it to the rest of the tree. You can check this by clicking the 'to trunk' links starting at node 2045877824.
Msnbot crawled from the disconnected node in upward and downward direction, creating a large subtree. This subtree caused the upward line between level 18 and 30 in figure 3.
The second large disconnected branch, at the top in the middle, originated from a link on uu-dot.com. Both disconnected branches are clearly visible in the Googlebot tree as well.
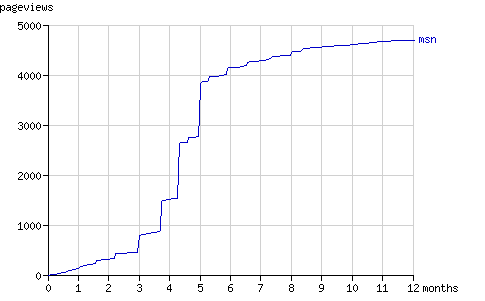
Fig. 13 - The cumulative number of pageviews by msnbot in time.
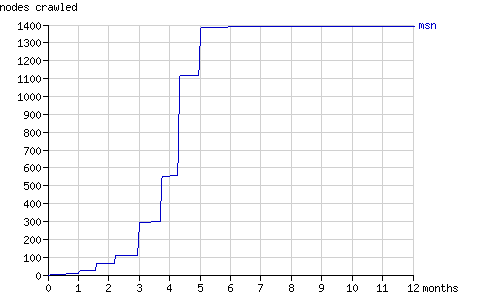
Fig. 14 - The cumulative number of nodes crawled by msnbot in time.
As the graphs above show, msnbot virtually ceased to crawl Binary Search Tree 2 after five months. How the number of results MSN Search returns, relates to the above graphs is unclear.
Spam bots
In one year 5265 comments were posted to 103 different nodes. 32 of these nodes were never visited by any of the search bots. Most comments (3652) were posted to the root node (the home page). The word frequency of the submitted comments was calculated.
| count | word | |
|---|---|---|
| 1 | 32743 | http |
| 2 | 23264 | com |
| 3 | 12375 | url |
| 4 | 8636 | www |
| 5 | 5541 | info |
| 6 | 4631 | viagra |
| 7 | 4570 | online |
| 8 | 4533 | phentermine |
| 9 | 4512 | buy |
| 10 | 4469 | html |
| 11 | 3531 | org |
| 12 | 3346 | blogstudio |
| 13 | 3194 | drunkmenworkhere |
| 14 | 2801 | free |
| 15 | 2772 | cialis |
| 16 | 2371 | to |
| 17 | 2241 | u |
| 18 | 2169 | generic |
| 19 | 2054 | cheap |
| 20 | 1921 | ringtones |
| 21 | 1914 | view |
| 22 | 1835 | a |
| 23 | 1818 | net |
| 24 | 1756 | the |
| 25 | 1658 | buddy4u |
| 26 | 1633 | of |
| 27 | 1633 | lelefa |
| 28 | 1580 | xanax |
| 29 | 1572 | blogspot |
| 30 | 1570 | tramadol |
| 31 | 1488 | mp3sa |
| 32 | 1390 | insurance |
| 33 | 1379 | poker |
| 34 | 1310 | cgi |
| 35 | 1232 | sex |
| 36 | 1198 | teen |
| 37 | 1193 | in |
| 38 | 1158 | content |
| 39 | 1105 | aol |
| 40 | 1099 | mime |
| 41 | 1095 | and |
| 42 | 1081 | home |
| 43 | 1034 | us |
| 44 | 1022 | valium |
| 45 | 1020 | josm |
| 46 | 1012 | order |
| 47 | 992 | is |
| 48 | 948 | de |
| 49 | 908 | ringtone |
| 50 | 907 | i |
complete list (360 kB)
As the top 50 clearly shows, most spam was related to pharmaceutical products. The pie chart below shows the share of each medicine.
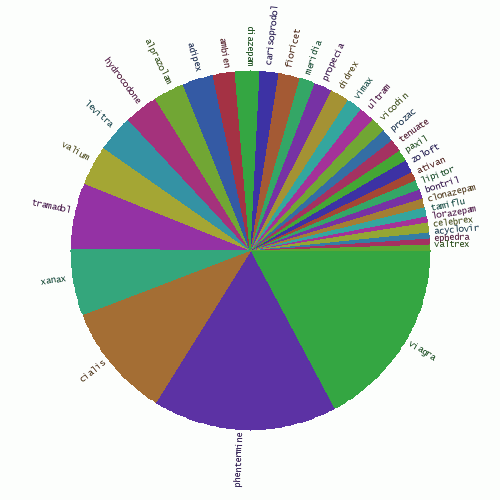
Fig. 15 - The share of various medicines in comment spam.
Submitted domain names were filtered from the text. All top-level domain names are shown in figure 16, ordered by frequency.
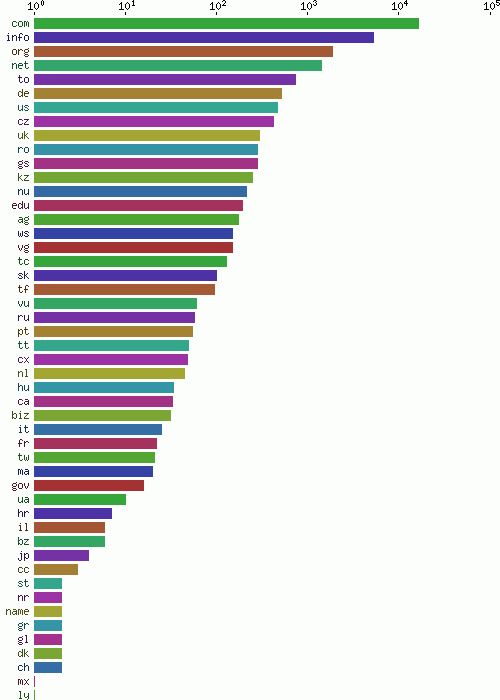
Fig. 16 - Number of spammed domains by top level domain
Many email addressses submitted by the spam bots were non-existing addresses @drunkmenworkhere.org, which explains the high rank of this domain in the chart of most frequently spammed domains (fig. 17).
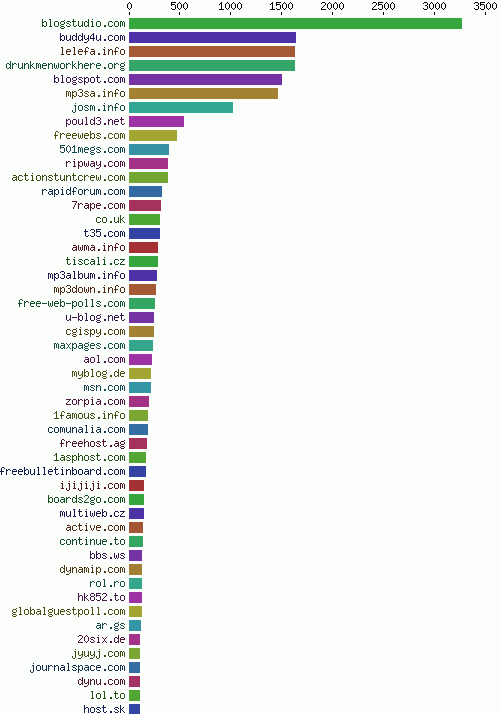
Fig. 17 - Most frequently spammed domains